
Headless Chrome, paired with something like Puppeteer is a powerful tool. There are a lot of use cases from interface testing to thumbnail and PDF generation. While valuable, it is a bottomless pit of despair because of technical details. We have been running millions of Headless Chrome jobs on Restpack and here are some observations and tips others;
Use Containers
It is a good idea to use docker containers because headless chrome requires a lot of dependencies and you will also need to install additional fonts, maybe some post processing tools for PDF / Screenshot generation and Docker makes it easier to manage these dependencies.
Puppeteer documentation has a great section on this but the general idea is that you’ll need to run everything on a non-root user to avoid --no-sandbox. Install some additional fonts for multi language rendering and emoji support. And also use an init system to avoid the horde of zombie processes chrome leaves behind.
Do not use multiple pages on a single browser
While it seems like a good idea to create a single browser with multiple pages for each operation, it does not work as well in practice.
There are some areas where Puppeteer will need to switch contexts and serialize operations on a single browser so let’s say you wish to create 10 screenshots, even if you manage to load 10 pages, actual capturing process (which is the slowest operation btw) will need to be serialized. This negates a lot of gains.
Also, browser pagesshare the same user data, same cache, same basic auth credentials. If you need to isolate operations from eachother, using multiple browsers makes life a lot easier. Puppeteer creates / cleans up temporary user directories for each browser.
let browser;
try {
browser = await puppeteer.launch();
let page = await browser.newPage();
await page.goto("https://example.com");
await page.screenshot({ path: "example.png" });
} finally {
if (browser) await browser.close();
}
Do not use Incognito Contexts
Following the previous points, you might be tempted to use incognito browser contexts for further isolation. However incognito contexts can be detected pretty easily by websites and some tend to act differently in case of an incognito visitor.
Even if you control the target websites / pages and this is not an issue, our observations show that incognito contexts have a higher resource impact. We have not dig deeper into the issues but while capturing millions of web pages each month, it is easier to spot resource consumption differences. Our tests with incognito contexts shows that it is better to use temporary browsers with ephemeral user directories.
Launching browsers is slow
While it is a good idea to use and destroy browsers for each operation, they are not instant to launch.

It is a good idea to use some kind of a pooling solution such as generic-pool for node and create browsers ahead of time, asynchronously. When you need them, it is best to have a browser ready to go.
let pool = genericPool.createPool(
{
create() {
return puppeteer.launch();
},
validate(browser) {
return Promise.race([
new Promise((res) => setTimeout(() => res(false), 1500)),
browser
.version()
.then((_) => true)
.catch((_) => false),
]);
},
destroy(browser) {
return browser.close();
},
},
{
min: 2,
max: 10,
testOnBorrow: true,
acquireTimeoutMillis: 15000,
}
);
Creating such a pool makes sure that at least 2 browsers are ready to be acquired. Also, we have a validate call that asks for browser version to ensure that the target browser is alive and kicking before handing it out to a worker job.
Request Interception is awesome
Puppeteer provides a comprehensive request interception feature where you can get notified about each request. You can decide to modify / abort / continue a request or simply override the network stack and return responses programmatically.
Even though there are infinite use cases, here are some that we make use of:
Ad Blocking
Request interception allows the programmer to abort requests selectively. In case of ad blocking, it is as simple as parsing the hostname, checking if it should be blocked and aborting the request if so;
page.on("request", (req) => {
let hostname = url.parse(req.url()).hostname;
if (blockedhosts.match(hostname)) {
req.abort();
} else {
req.continue();
}
});
Here, the blockedhosts data structure should determine if a given hostname is an ad server. You can use a simple array and fill it with open hosts.txt databases for matching ad servers.
Proxying
It is possible to launch browsers with proxy settings but if you wish to handle selective proxying (say, you want to proxy the actual document but not sub assets) it can be achieved by intercepting each request, handling the request yourself, using whatever proxying method you wish to use. In our case we offer geo locations where our users can choose to capture pages from IP addresses all around the world. Request interception makes it possible to use an already launched browser, intercept requests and proxy appropriate ones via a selected node.
Bandwidth monitoring / Limiting
If you wish to be able to limit data transfer or simply measure it, you can simply listen for responseevents on a page and sum up the buffer sizes.
Handling Lazy Loading Images
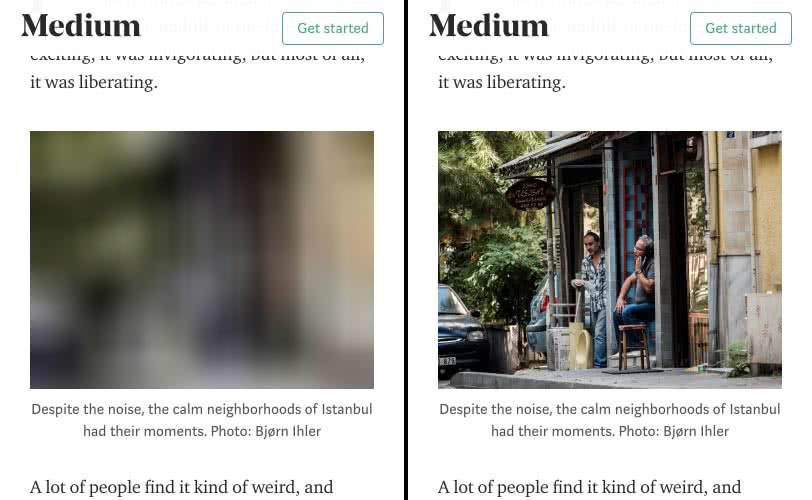
If you have lazy loaded images on the pages that you want to capture as an image of PDF, they will end up as empty placeholders in the resulting document.
Puppeteer captures full page screenshots by resizing the viewport to the content size. However there is next to no delay between this process and actual capturing of the page. So, even if the lazy loader script catches up to this resize event, images will almost certainly have no time to load.
Also, it seems like a lot of lazy loading scripts do not handle resize events correcly but just handle scroll events.
It is easier to scroll the page down in segments before capturing, something like this:
function preScroll(page) {
return page.evaluate(() => {
return new Promise((res) => {
let height = document.body.scrollHeight;
let win = window.innerHeight;
let count = Math.ceil(height / win);
function tick() {
if (count < 0) {
window.scrollTo(0, 0);
return res();
}
window.scrollTo(0, count * win);
count--;
setTimeout(tick, 100);
}
tick();
});
});
}
Avoid leaking information
If you are planning to feed user submitted URLs / HTML to your headless chrome instances, you need to make sure that the instance can not access sensitive information. One example is allowing file:// protocol urls. Do not allow this. One can screenshot files ranging from /etc/passwd to god knows what.
Also, let’s say you are running this on an AWS EC2 instance. EC2 instances can access a local metadata service located on 169.254.169.254. You need to make sure that the chrome instance can not access this kind of local services.
Conclusion
While there are tons of tips and tricks of running a cluster of Headless Chrome workers. These should help you tackle some of the problems.